
2026年5月14日,中国医学科学院基础医学研究所龙尔平/庞军玲团队在 npj Digital Medicine 《自然合作期刊·数字医学》杂志发表了题为“A foundational model encodes deep phenotyping data and enables diverse downstream applications”(面向深度表型数据的基础模型及其多样化下游应用)的研究论文,研发了面向深度表型数据的基础模型,让大模型像读句子一样读懂健康档案,解码疾病分型、重构共病网络、预测患病风险。
医院里的电子病历、体检报告、生活方式问卷,数据格式各异、条目顺序混乱,传统模型很难统一处理。该模型从底层重新设计了一套“健康语言编码系统”。它将每一条健康信息拆解为“特征词元”和“取值词元”。例如“血常规”是一个特征,“偏高”是一个取值,两者配对形成一个“词”。所有健康条目无论以什么顺序出现,模型都通过“位置无关嵌入”技术准确理解其含义。这样一来,个体的全部健康档案就被组织成一段“描述健康的文章”,大模型读懂这些“文章”后,就可以用于疾病分型、共病分析和风险预测等多种任务。这套框架天然适配真实医院中数据不规整、条目不固定的场景。
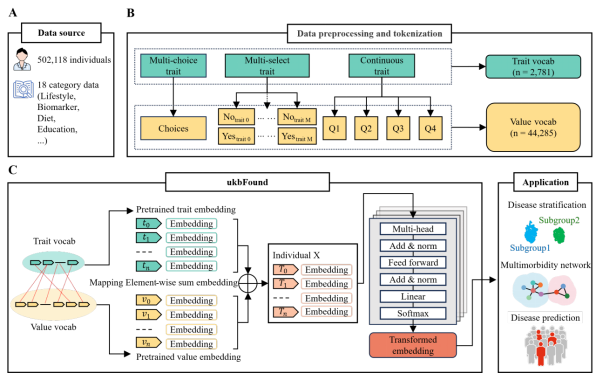 深度表型基础模型的框架示意图
深度表型基础模型的框架示意图
慢性阻塞性肺疾病(慢阻肺病)长期缺乏公认分型标准,该模型将患者自动分为“平稳集中”与“两极震荡”两种嗜碱性粒细胞分布模式,两种“健康语法”对应显著不同的预后,10年生存率绝对差异达4.5%,且基线呈“两端分布”者后续肺功能(FEV1)下降更明显,提示该分布特征可能成为慢阻肺病进展的新风险指标。同样的分析框架也被用于探索疾病间关联,传统研究多关注两两共病,而该研究将视角提升至“疾病社区”层面,从四百余种非癌疾病中识别出超三万个共病关系,挖掘出上千组此前未报道的候选共病关系(如低血小板障碍与痛风、Graves病与心肌炎),并归纳出呼吸社区(慢阻肺病、睡眠呼吸暂停等)和心血管社区(高血压、心律失常等),为理解多病共存的共享机制提供了新框架。进一步地,该模型还能仅基于465个生活方式和饮食特征有效预测143种疾病,平均AUC达0.82,较10个基准模型提升0.03–0.16,纵向随访中痛风最高风险组后续发生率为5.6%(比值比约17.5),表明日常信息可转化为未来患病风险图谱,助力早期识别与精准预防。
该研究是一套可以适配医院电子病历、体检队列和健康管理平台的通用底层框架。它通过特征-取值对偶词元化、位置无关嵌入和分层Transformer编码,实现了对复杂、异构、不规整健康数据的统一建模。同一个模型表征可以同时用于疾病内部分型、共病网络构建和后续患病风险预测,其代表的“健康语言化”思路,为利用日常医疗数据开展精准医学研究打开了一扇新的大门。
该研究得到中国医学科学院医学与健康科技创新工程(2023-I2M-3-010, 2025-I2M-XHXX-069)、中国医学科学院基本科研业务费(2023-JKCS-20)、呼吸和共病全国重点实验室专项经费(2060204)等项目支持。基础医学研究所洪奇阳和王聪为该论文的共同第一作者,庞军玲与龙尔平为共同通讯作者。
原文链接:https://www.nature.com/articles/s41746-026-02736-w
供稿:专项处

